这是一个机器学习的系列,偏数据分析方向,未来或许会写一些偏人工智能方向的机器学习的文章。这个系列将会详细介绍常用的机器学习模型和算法,像是线性回归和分类算法。最后会介绍机器学习方向合适的一些可视化工具。
我是程序员出身,这个系列中所有的代码我会用Python和R语言同时演示,但是算法的内部逻辑运算我也会用Java或者Python演示。也就是说从这个系列中你不仅仅可以学会如何使用Python和R进行机器学习,也可以用习惯的编程语言编写自己的机器学习库。
现在就让我们进入机器学习的世界吧!
这一节主要进行机器学习的入门。内容比较基础。
编程环境的话依个人喜好而定,我也不会推荐任何IDE,但是我会贴出代码。
获得数据集(get the dataset)
在做机器学习之前需要有结构化的数据(structure data)才行。网上有很多网站可以提供这些数据。我也会给大家提供一些简单的数据集。
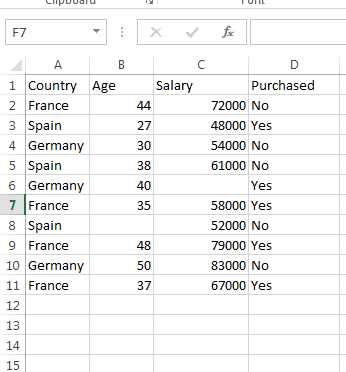
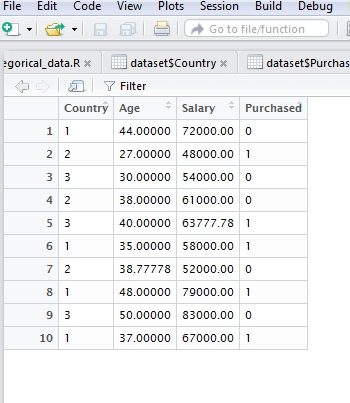
首先我们使用一个简单的数据集。每一个数据集都会包括两部分,独立变量(independent variable)和依赖变量(dependent variable)。机器学习的目的就是需要通过独立变量来预测非独立变量(prediction)。 独立变量不会被影响而非独立变量可能被独立变量影响。
在以下数据集中Age和Salary就是独立变量,我们需要通过这两个独立变量预测是否会Purchase。所以Purchased就是非独立变量。
导入数据科学库(importing the library)
下面我们要准备Python的编程环境,在Python中有很多数据科学的库(见我的Data Scienc系列),我们需要的主要是以下三个库:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
导入数据集(importing dataset)
在导入数据之前你需要设置working directory, 就是将代码与数据保存在同一文件夹下。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Data.csv') #可以选中salary,点击Format, 改成 %0f 。
机器学习或者说数据科学中很重要的一点就是建立metrics(度量,指标)。每一列都可以是一个metric。
metrics主要包括两部分:independent variable 和 dependent variable。
# create 独立变量vector
X = dataset.iloc[:, :-1].values # 第一个冒号是所有列(row),第二个是所有行(column)除了最后一个(Purchased)
# create 依赖变量vector
Y = dataset.iloc[:, 3 ].values # 只取最后一个column作为依赖变量。
# 设置working directory
getwd()
setwd("/Users/ML1/")
dataset = read_csv('Data.csv')
View(dataset)
处理空数据(Missing Data)
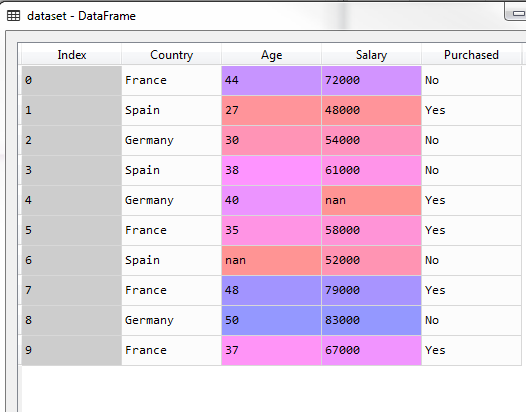
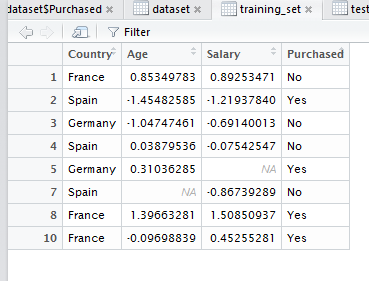
在数据集中可能会出现为空的数据,我们不能删除有空数据的列,这样会对我们机器学习的结果造成影响,在data science中我们可以用NaN代替空值,但是在ML中必须要求数据为numeric。所以我们可以用mean来代替空值。
原数据集如图:
代码如下:
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
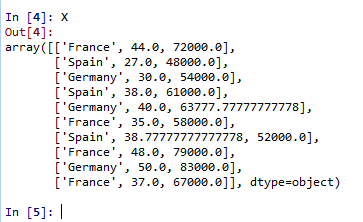
# Taking care of missing data
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0)
imputer = imputer.fit(X[:, 1:3]) # (inclusive column 1, exclusive column 3, means col 1 & 2)
X[:, 1:3] = imputer.transform(X[:, 1:3]) # 将imputer 应用到数据
结果如下图所示:
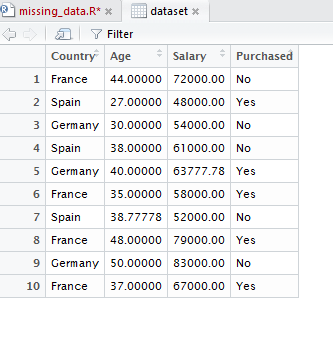
R 语言代码如下:
# Data Preprocessing
# Importing the dataset
dataset = read.csv('Data.csv')
# Taking care of missing data
dataset$Age = ifelse(is.na(dataset$Age),
ave(dataset$Age, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Age)
dataset$Salary = ifelse(is.na(dataset$Salary),
ave(dataset$Salary, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Salary)
分类数据(category data)
在对数据集进行处理时候我们会遇到一些包含同类别的数据(如图二中的country)。这样的数据是非numerical的数据,所以我们可以用数字来代替,比如不同的国家我们可以用1,2,3区分不同国家,但是这样会出现一个比较严重的问题。就是国家之间的地位是相同的,但是数字有顺序大小之分。所以我们用另一种方法,就是将不同的类别(如不同国家)另外分为一个列,属于这个国家的设置为1,不属于的设置为0.:
# Encoding categorical data
# Encoding the Independent Variable
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0]) #不包括index行
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
# Encoding the Dependent Variable
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
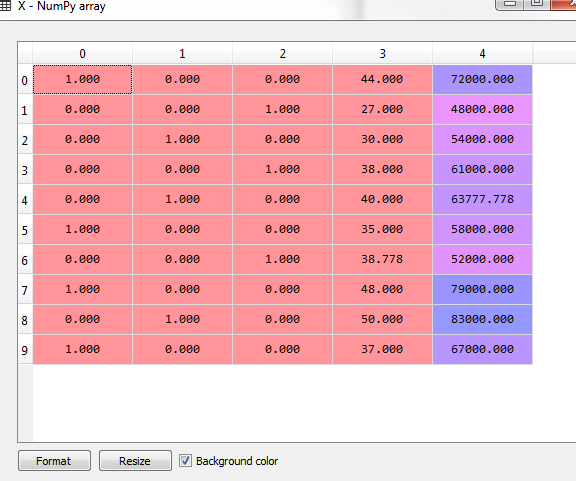
在R语言中不需要特别将每一类别分为一列,这比Python要简单一些。因为每一列用vector来表示,所以可以接受不同的大小。
# Encoding categorical data
dataset$Country = factor(dataset$Country,
levels = c('France', 'Spain', 'Germany'),
labels = c(1, 2, 3))
dataset$Purchased = factor(dataset$Purchased,
levels = c('No', 'Yes'),
labels = c(0, 1))
将数据集分类
当数据集准备完成之后,我们需要将数据集进行分类,将独立变量和依赖变量分为训练集和测试集。训练集与测试集的比例一般是用4:1。
# Splitting the dataset into the Training set and Test set
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
特征缩放(feature scaling)
这是对数据处理的一项很重要的步骤,在机器学习中,由于每个变量的范围不同,如果两个变量之间差距太大,会导致距离对结果产生影响。所以我们要对数据进行一定的标准化改变。最简单的方式是将数据缩放至[0.1]或者[-1,1]之间:
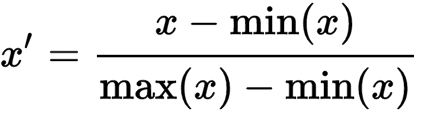
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
# Feature Scaling
training_set[, 2:3] = scale(training_set[, 2:3])
test_set[, 2:3] = scale(test_set[, 2:3])
建立模板
以上就是几个基本的准备工作的步骤,我们可以建立一个样板,对数据进行预处理,然后在进行机器学习,以下是Python和R的样板:
# Data Preprocessing template
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
# Splitting the dataset into the Training set and Test set
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
# Data Preprocessing template
# Importing the dataset
dataset = read.csv('Data.csv')
# dataset = dataset[, 2:3]
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[, 2:3] = scale(training_set[, 2:3])
test_set[, 2:3] = scale(test_set[, 2:3])
下面我们就开始真正的机器学习啦!!